By now, you understand what artificial intelligence is, how tokens work, and why context windows and pricing matter. The natural next question is: which AI model should you actually use?
The answer, as you might suspect, is that it depends. The AI landscape is crowded, fast-moving, and full of options. New models are released regularly, existing ones are updated frequently, and the performance rankings shift with every major release. If you try to keep up by memorizing specific model names and version numbers, you will be in a constant state of catch-up. That is not a winning strategy.
What does work is understanding the underlying structure of the landscape. When you know how model families are organized, what distinguishes one type of model from another, and how to evaluate which model fits a particular use case, you can navigate new releases with confidence regardless of how quickly the space evolves. That is the goal of this article: to give you a durable framework for thinking about large language models that will serve you well no matter what gets released next month or next year.
Why Model Selection Matters
Before we dive into the specifics, it is worth understanding why this topic deserves an entire article. When you are just getting started with AI, it is tempting to pick one model and use it for everything. And for casual personal use, that approach works well enough. But the moment you begin building AI-powered systems for your business, for clients, or at any kind of scale, model selection becomes one of the most consequential decisions you will make.
As you learned in the previous article, pricing is based on token usage, and costs vary enormously from one model to another. Context limits are measured in tokens, and those limits differ across models as well. Beyond cost and capacity, models also vary in their speed, accuracy, reasoning ability, and suitability for different types of tasks. Choosing the wrong model for a given job is like using a sledgehammer to hang a picture frame. It might technically get the job done, but the cost, the collateral damage, and the inefficiency make it a poor decision.
The good news is that you do not need to become an expert on every model available. You need to understand the categories, the trade-offs, and the decision-making framework. Once you have that, you can evaluate any model, current or future, with clarity.
Parameters: The Size of the Brain
When you read about AI models, you will frequently encounter a number followed by the word “parameters,” as in “a seven billion parameter model” or “a 236 billion parameter model.” This number is worth understanding at a high level, even though you never need to know the mathematical details behind it.
Parameters are the internal numerical values that a model learns during its training process. Think of them as the model’s accumulated knowledge, stored as millions or billions of tiny weights and connections. The more parameters a model has, the more patterns it can store, the more nuance it can capture, and the more complex the tasks it can potentially handle. In very rough terms, parameters represent the size of the model’s brain.
A smaller model with a few billion parameters will be faster, lighter, and cheaper to run. It can handle straightforward tasks quickly and efficiently, but it may struggle with deeply complex reasoning or highly nuanced language. A larger model with hundreds of billions of parameters will be more capable and versatile, but it will also be slower and more expensive. It requires significantly more computing power to operate, which is reflected in higher API costs and longer response times.
You do not need to memorize parameter counts for specific models. What matters is the principle: model size is a trade-off between capability and cost. Bigger is not always better. The right choice depends on the task.
Two Fundamental Model Types: Standard and Reasoning
Across the entire AI landscape, regardless of which company built the model, you can broadly categorize large language models into two types: standard LLMs and reasoning LLMs. Understanding this distinction is one of the most practical things you can learn about model selection, because it directly affects how you choose which model to deploy for a given task.
Standard LLMs
Standard large language models are designed for fast, general-purpose text generation. They process your input and produce output quickly, generating tokens at a rapid pace with minimal delay. These are the workhorses of the AI world, and for the majority of everyday tasks, they are exactly what you need.
Standard models excel at things like writing and editing content, answering questions, summarizing documents, performing quality assurance checks, handling customer inquiries, generating marketing copy, and powering conversational chatbots. They are responsive, efficient, and cost-effective. When you interact with most AI tools in a casual setting and get a near-instant response, you are typically using a standard model.
Reasoning LLMs
Reasoning models take a fundamentally different approach. Instead of generating output immediately, they first engage in an internal deliberation process, essentially “thinking” through the problem step by step before producing a response. If you have used a chatbot and noticed it display a message like “Thinking…” followed by a pause of several seconds before responding, you have experienced a reasoning model at work.
This deliberation comes at a cost: reasoning models are slower and more expensive than their standard counterparts. But the trade-off is significantly improved accuracy on complex tasks. They are better suited for advanced mathematics, multi-step logical problems, intricate coding challenges, scientific analysis, strategic planning, and any situation where careful, step-by-step thinking produces a meaningfully better result than a quick response.
The key insight here is that you should match the model type to the task. If you are classifying emails, drafting social media posts, or generating routine summaries, a standard model will handle it quickly and cheaply. If you are auditing a financial report, debugging complex code, or building a detailed strategic proposal, a reasoning model’s slower, more deliberate approach will deliver substantially better results. Using a reasoning model for simple tasks wastes money and time. Using a standard model for complex reasoning tasks produces inferior output. Knowing when to use which type is a skill that will save you significant resources.
It is worth noting that the line between these two categories is not always rigid. Some models function as hybrids, offering a general-purpose mode for straightforward tasks and an optional “deep thinking” mode that you can enable when you need more thorough reasoning. This flexibility is becoming increasingly common and gives you the ability to toggle between speed and depth depending on what the moment requires.
The Major Model Families: Understanding the Big Three
The AI landscape includes models from dozens of companies, but three providers currently dominate the proprietary, closed-source space: OpenAI, Anthropic, and Google. Each company organizes its models into families with distinct naming conventions that, once you understand them, tell you a great deal about what a model is designed to do. Importantly, even as new versions are released, the naming structure and the logic behind it tend to remain consistent. That means learning the family structure once gives you a lasting advantage.
OpenAI
OpenAI organizes its models into three primary families.
The GPT family represents their general-purpose language models. These are the models most people associate with OpenAI, and they form the backbone of ChatGPT. They are versatile, capable across a wide range of tasks, and continuously improved with each new release. When OpenAI releases a new GPT model with a higher number, you can generally expect broader capabilities and improved performance.
The Turbo family consists of speed-optimized variants of the GPT models. Turbo models are designed to deliver faster responses at a lower cost, making them ideal for applications where speed and affordability matter more than maximum capability. If you see “Turbo” in a model name, think “lighter, faster, cheaper.”
The O-Series represents OpenAI’s dedicated reasoning models. These are their thinking-first, deliberative models built specifically for tasks that require careful step-by-step logic. If you see a model name that begins with “O” followed by a number, you know immediately that it is a reasoning model. Understanding this naming convention means that whenever OpenAI releases a new O-Series model, you already know what it is designed for, without needing to read a single press release.
Anthropic
Anthropic, the company behind Claude, follows a similar three-tier structure.
Sonnet models are their general-purpose workhorses. They offer strong all-around performance and are the models most people interact with in everyday use. Sonnet models are also capable of some degree of deeper thinking when you enable extended reasoning, which is why some people consider them hybrid models that straddle the line between standard and reasoning categories.
Haiku models are the speed-optimized tier. They are the fastest and most affordable models in Anthropic’s lineup, designed for tasks where rapid response times and low cost are the priorities. If you need to process high volumes of relatively simple tasks, Haiku models are typically your best choice within the Anthropic ecosystem.
Opus models are Anthropic’s heavyweight reasoning models. They offer the deepest deliberation, the largest context handling, and the most sophisticated analysis, but they are also the most expensive and slowest to respond. Opus is what you reach for when the quality and depth of reasoning justify the premium cost.
Google’s Gemini model family follows a three-tier structure as well, though with slightly different naming.
Pro models are Google’s flagship offerings, positioned as their most capable models for complex reasoning and advanced tasks. They serve as a general-purpose, high-capability tier that can handle sophisticated analysis while also being versatile enough for a wide range of applications.
Flash models are the performance-optimized tier, balancing strong capability with impressive speed and low cost. Flash models are frequently cited as some of the fastest and most affordable models available in the entire market, making them extremely attractive for high-volume applications where you need reliable performance without premium pricing.
Flash-Lite models sit at the entry level, designed for massive-scale, text-only workloads where the absolute lowest cost per token is the priority. These are the models you would consider for bulk processing tasks that do not require advanced reasoning or multimodal capabilities.
At a glance, here is how the naming conventions map across the three major providers. Note: These models change over time. So do search the web for the latest model.
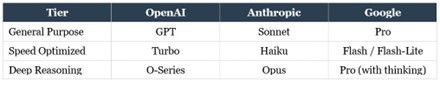
Once you internalize this table, you will be able to look at any new model release from these three companies and immediately understand where it fits. A new Haiku model? Fast and cheap. A new O-Series model? Deep reasoning. A new Flash model? Speed at a great price. This knowledge is evergreen, even as specific version numbers change constantly.
Beyond the Big Three: Open-Source and Alternative Models
OpenAI, Anthropic, and Google are not the only players in the field. It is important to understand the broader landscape, particularly the distinction between closed-source and open-source models.
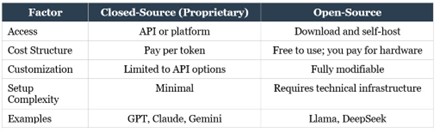
The models from the Big Three are proprietary and closed-source. This means you access them through their platforms or APIs, they run on the company’s servers, and you cannot see or modify the underlying code. You pay per token, and you trust the provider to manage the infrastructure, security, and updates. For most users and most use cases, this is perfectly fine and is the simplest way to get started.
Open-source models, on the other hand, offer a different set of advantages. Models like Meta’s Llama and DeepSeek are freely available for anyone to download, inspect, modify, and run on their own hardware. This means you can host them on your own servers or even on a powerful local machine, eliminating per-token API costs entirely. For organizations with high-volume usage, this can translate into dramatic cost savings. Open-source models also offer greater customizability, since you can fine-tune them for specific tasks or domains in ways that closed-source APIs do not allow.
The trade-off is complexity. Running open-source models locally requires understanding hardware requirements such as RAM, GPU capacity, and storage. It requires managing the infrastructure yourself, handling updates, and troubleshooting issues without the safety net of a provider’s support team. For most people starting their AI journey, closed-source models through APIs are the path of least resistance. But as your usage scales and your technical confidence grows, open-source models become an increasingly attractive option.
There are also other proprietary models worth being aware of, such as Grok from xAI, which offers features like real-time data integration and large context windows. The landscape is broad and growing broader every day, which is all the more reason to focus on understanding categories and trade-offs rather than memorizing specific products.
Here is a quick comparison of the two approaches.
Cost-Saving Strategies for Model Usage
As you begin working with multiple models and building systems that process significant volumes of data, cost management becomes increasingly important. Here are several proven strategies for keeping your AI expenses under control without sacrificing quality.
The first and most impactful strategy is right-sizing your models. This means using smaller, more affordable models for simpler tasks and reserving powerful, expensive models for work that genuinely requires their capabilities. If you are classifying incoming emails by topic, you do not need a premium reasoning model. A lightweight, fast model will handle it at a fraction of the cost. Save the heavy hitters for tasks like complex audits, detailed strategic proposals, or multi-step analytical work where their superior reasoning justifies the expense.
The second strategy is to reduce your token consumption through smarter inputs and outputs. Instead of feeding an entire document to a model, consider sending a summary of the key points. Instead of allowing the model to generate lengthy, open-ended responses, specify a concise output format. You can instruct the model to focus only on the most important words or to deliver its answer within a specific word count. Every token you save on input and output is money you keep in your pocket.
The third strategy is prompt caching. When you find yourself sending the same or very similar prompts repeatedly, caching the repeated content can save you up to ninety percent on redundant processing. This is particularly valuable in automated systems where the same system instructions or context documents are included in every request.
The fourth strategy is batch processing. Many AI providers offer significant discounts, often around fifty percent, when you queue non-urgent tasks for batch processing rather than demanding real-time responses. If your workflow does not require instant results, batching can cut your costs dramatically.
And the fifth strategy, as we discussed, is deploying open-source models for high-volume workloads. When your usage is heavy enough to justify the infrastructure investment, eliminating per-token API costs by self-hosting can deliver substantial long-term savings.
Matching the Right Model to the Right Task
One of the most common questions people ask when they start working with AI is: “What is the best model?” The honest answer is that there is no single best model. There is only the best model for a specific task, and that answer changes depending on several factors.
When evaluating which model to use, you should consider the following questions. How much context are you dealing with? If you are processing long documents, you need a model with a large context window. If your inputs are short, you can use a model with a smaller window and save money. How important is speed? For customer-facing applications where response time matters, a fast, speed-optimized model is essential. For background processing where no one is waiting, speed is less of a concern. How complex is the reasoning required? Simple classification and extraction tasks do not justify a reasoning model. Multi-step analysis and strategic thinking do. What is your budget? A premium model that delivers excellent results is useless if it costs more than the value it creates.
The ability to answer these questions and match models accordingly is ultimately more valuable than knowing the specifications of any individual model. Specifications change constantly. The decision-making framework does not.
Staying Current: Tools for Comparing Models
Given how rapidly the AI landscape evolves, it helps to have reliable resources for staying up to date on model performance and rankings. Two tools are particularly useful.
The first is the Vellum LLM Leaderboard, which provides regularly updated benchmark comparisons across major models. You can see at a glance how different models rank in categories like mathematical reasoning, agentic coding, tool use, adaptive reasoning, overall performance, speed, and cost-effectiveness. The leaderboard also allows you to compare two models head-to-head, examining differences in context window size, knowledge cutoff date, input and output costs, latency, speed, and maximum output length. Think of it as the equivalent of a side-by-side product comparison when you are shopping for electronics. It gives you a structured, objective basis for evaluating your options.
A quick note on cutoff dates: when you see a “knowledge cutoff” or “training data cutoff” listed for a model, it refers to the date through which the model’s training data extends. If a model has a cutoff of a particular date, it means the model has no awareness of events or information that occurred after that date. This is important to keep in mind when you are working with time-sensitive information.
The second tool is LM Arena, which takes a community-driven approach to model evaluation. Users chat with different models in blind tests, meaning they do not know which model is generating each response, and then vote on which output they preferred. The aggregated results produce a crowdsourced ranking across categories, including general text quality, vision capabilities, image generation, image editing, search performance, and more. This gives you insight into how real users experience different models in practice, complementing the more technical benchmark data from resources like the Vellum Leaderboard.
Between benchmark leaderboards and community-driven evaluations, you have access to a rich, constantly updated picture of the AI model landscape. Make a habit of checking these resources periodically, especially before making decisions about which models to integrate into your workflows.
The Framework That Matters
Let us close this article by crystallizing the framework you should carry forward. The AI model landscape will continue to shift. New models will be released. Existing ones will be updated or deprecated. Pricing will change. Performance benchmarks will be rewritten. None of that should overwhelm you, because you now have something more durable than knowledge of any specific model: you have a way of thinking about models.
You understand that models vary in size and that larger models offer more capability at a higher cost. You know the difference between standard models built for speed and general-purpose tasks, and reasoning models built for careful, step-by-step deliberation. You can identify the three major proprietary families and decode their naming conventions to instantly understand what a new release is designed for. You appreciate the distinction between closed-source and open-source models and the trade-offs each involves. You have strategies for managing cost. And you know where to go to compare models objectively when it is time to make a decision.
This framework does not expire. It will serve you just as well six months or two years from now as it does today. The specific names and numbers will change. The principles will not. And that is exactly the kind of knowledge that creates lasting advantage.