In the previous article, you learned how to navigate the landscape of large language models by understanding model families, naming conventions, and the difference between standard and reasoning models. Now it is time to address another fundamental distinction that will shape how you build, deploy, and pay for your AI-powered systems: the difference between open-source and closed-source models.
This is not just a technical distinction. It is a strategic decision that affects your costs, your control over your data, your privacy posture, your ability to customize, and your long-term dependence on third-party providers. Whether you are building AI tools for your own business or advising clients on their AI strategy, understanding the trade-offs between these two approaches is essential.
And here is something important to keep in mind: the concept of open source versus closed source extends well beyond AI models. It applies to software platforms, automation tools, and many of the technologies you will encounter in the AI ecosystem. A solid understanding of what each term means and what it implies will serve you across multiple dimensions of your work.
What Is a Closed-Source LLM?
A closed-source large language model is a proprietary system developed privately by a company. The training data, the internal weights, the code, and the optimization techniques that power the model are all kept confidential. You, as the user, do not have access to any of the underlying architecture. What you have access to is the model’s output, delivered through either a web interface or an API.
The major closed-source model providers today include OpenAI, Anthropic, and Google. When you open a chatbot interface in your browser, select a model, and type a question, what happens behind the scenes is straightforward. Your input is sent over the internet to the provider’s servers. The model processes your input on their infrastructure, generates a response, and sends that response back to you. Your input tokens travel to their servers, the model does its work, and the output tokens travel back. The entire process is managed, maintained, and controlled by the company that built the model.
When you access these same models through an automation platform or a custom application, the mechanics are the same. Your system sends an API call to the provider, the model processes the request, and the response comes back. Every interaction is a round trip to someone else’s infrastructure.
This has significant implications for how you think about cost, data privacy, and control, all of which we will examine in detail.
The Advantages of Closed-Source Models
State-of-the-Art Performance
The companies behind closed-source models have invested billions of dollars in research and development. They employ some of the world’s leading AI researchers, they have access to vast computing resources, and they train their models on enormous datasets using cutting-edge techniques. The result is that closed-source models consistently represent the frontier of AI capability. When a new breakthrough in reasoning, coding, or language understanding occurs, it almost always appears first in a closed-source model.
Open-source alternatives do exist, and some of them are remarkably capable. But they typically lag behind the closed-source leaders by some margin, simply because they are developed with fewer resources. Occasionally, an open-source release disrupts this pattern and delivers near-parity performance at a fraction of the cost, which sends shockwaves through the industry. But as a general rule, if you want access to the absolute best-performing model available at any given moment, it will usually be a closed-source offering.
Dedicated Support and Managed Infrastructure
When you use a closed-source model, the provider handles everything on the backend. Server infrastructure, uptime, stability, security patches, software updates, regulatory compliance, and performance optimization are all their responsibility, not yours. You do not need to think about how much RAM is required, what kind of GPUs are needed, or how to scale the infrastructure as demand grows. All of that complexity is abstracted away.
This is an enormous advantage, especially when you are starting out. It means you can focus entirely on building your AI-powered workflows and solving business problems, without getting dragged into the weeds of infrastructure management. For many individuals and businesses, this convenience alone is reason enough to stick with closed-source models.
Quality Assurance and Safety
Closed-source model providers invest heavily in testing, evaluation, and alignment. They implement safety guardrails designed to reduce harmful outputs, they work to ensure the model’s responses align with human values, and they continuously refine the model’s behavior based on user feedback and internal evaluation. While no model is perfect, the rigorous quality assurance processes behind closed-source models mean you are working with a product that has been extensively vetted before it reaches you.
The Disadvantages of Closed-Source Models
Limited Control and Customization
Because the model’s internals are locked away, you cannot modify or deeply tailor how it works. You can influence its behavior through system prompts, which are instructions you provide to guide the model’s responses, and through a technique known as Retrieval-Augmented Generation, or RAG, which gives the model access to specific data sources to inform its output. These approaches allow a meaningful degree of customization.
However, you cannot change the model’s fundamental architecture, retrain it on your own proprietary data in a deep way, or alter its core behaviors beyond what the provider allows. Whatever decisions the company made during training, whatever biases exist in the training data, and whatever limitations are built into the model’s default behavior, you must accept those as they are. Fortunately, most providers offer multiple models within their family, giving you some ability to select the variant that best fits your needs. But the underlying engine is outside your control.
Higher Costs at Scale
Every time you interact with a closed-source model, you pay. Whether that payment takes the form of a monthly subscription for a chatbot interface or per-token charges on every API call, the costs are ongoing. For personal use or low-volume applications, these costs are manageable and often quite reasonable. But at scale, they can add up quickly.
Imagine you have built an automation that runs a thousand times per day, and each run involves the model generating a full email, a detailed summary, or a lengthy piece of content. The output token costs for those generations multiply rapidly. Suddenly, what seemed like an affordable per-token price becomes a significant monthly expense. This scaling dynamic is one of the primary reasons that businesses with heavy AI usage eventually explore open-source alternatives.
Privacy and Data Concerns
This is perhaps the most consequential disadvantage, and it deserves careful consideration. When you use a closed-source model, your data leaves your environment. Your prompts, your documents, your customer information, your internal communications, all of it travels over the internet to a third-party server where the model processes it. The provider is, in that moment, in possession of your data.
For many applications, this is perfectly acceptable. But for businesses that handle sensitive information, the implications are serious. If you are working with personally identifiable information, financial records, healthcare data, legal documents, or any information subject to regulatory compliance, sending that data through a third-party API introduces risk. There are data retention concerns, transparency gaps about how the data might be used, and compliance hurdles that can be extremely difficult to navigate in regulated industries.
Consider the situation many large enterprises face. A financial services firm, for instance, may see tremendous potential in AI-powered meeting transcription, document analysis, and automated reporting. But the nature of the data involved, including client financial details, proprietary strategies, and confidential communications, makes it impractical to route through an external model without extensive security and compliance review. In many cases, the firm would need to deploy its own model on its own infrastructure, trained and managed internally, before it could comfortably allow sensitive information to flow through an AI system. That level of investment and expertise is precisely what drives interest in open-source alternatives.
Dependency Risks
When you build your workflows around a closed-source model, you are dependent on the provider. If they raise their prices, you absorb the increase. If they change their policies or terms of service, you adapt or find an alternative. If they discontinue a model you rely on, you scramble to migrate. If they push an update that changes the model’s behavior in ways that affect your output quality, you have no way to revert to the previous version. This vendor dependency is a real strategic risk, especially for businesses that have deeply integrated a specific model into their operations.
What Is an Open-Source LLM?
An open-source large language model is one whose weights, and often its training methods, are made publicly available. Anyone can download the model, inspect how it works, modify it, retrain it on new data, and deploy it on their own infrastructure. The most prominent examples include Meta’s Llama family and DeepSeek, though the open-source ecosystem also includes models from other organizations and communities.
The access model is fundamentally different from closed-source. Instead of sending API calls to someone else’s server, you host the model yourself. It runs on your own hardware, whether that is a local machine, a private server, or a cloud instance that you control. Your data never leaves your environment. There are no per-token API charges. And you have full freedom to customize, retrain, and deploy the model however you see fit.
The Advantages of Open-Source Models
Complete Control
With an open-source model, you own your entire AI stack. You can modify the model’s architecture, adjust its tuning, add or remove safety layers, and tailor its behavior for highly specific use cases. If you need the model to respond in a particular way for a niche industry application, you have the ability to fine-tune it on your own proprietary data until it performs exactly as you need. This level of control is simply not possible with closed-source alternatives.
Cost Efficiency
Once you have the infrastructure in place, running an open-source model is essentially free beyond your compute costs. There are no per-query fees, no subscription charges, and no output token costs. Your expenses are predictable and tied to your hardware rather than your usage volume. For organizations with high-volume AI workloads, this economic model can deliver dramatically lower long-term costs compared to paying per-token on a closed-source API.
Privacy and Security
This is where open-source models offer their most compelling advantage for many organizations. Because the model runs on your own infrastructure, your data never leaves your environment. There is no third-party exposure, no data traveling across the internet to an external API, and no uncertainty about how a provider might retain or use your information. You have complete control over your security and compliance posture, which is critical for businesses operating in regulated industries or handling sensitive data.
Community Innovation
Open-source models benefit from a global community of developers and researchers who contribute improvements, share fine-tuning techniques, build complementary tools, and push the capabilities of these models forward. The iteration cycles can be remarkably fast, and you gain access to a wealth of community-driven knowledge and support that simply does not exist within the walled garden of a proprietary model.
The Disadvantages of Open-Source Models
Significant Technical Requirements
Running an open-source model is not a plug-and-play experience. You need adequate computing resources, which typically means powerful GPUs, sufficient RAM, and enough storage to handle the model’s parameter size. For larger models with hundreds of billions of parameters, the hardware requirements are substantial. Beyond the initial setup, you also need the infrastructure expertise to deploy, configure, and maintain the system. This often means having access to skilled DevOps personnel or infrastructure engineers who can troubleshoot issues, manage scaling, and ensure uptime.
If your locally hosted model goes down, there is no customer support hotline to call. Your workflows stop running until your team fixes the problem. That operational risk is a real consideration, especially for businesses where AI-powered processes are mission-critical.
Potential Performance Gap
Open-source models, while increasingly capable, are typically trained with fewer resources than their closed-source counterparts. They tend to be smaller, less extensively fine-tuned, and may lag behind the absolute frontier of AI performance. For many tasks, the difference is negligible, and an open-source model will perform admirably. But for tasks that demand the very best in reasoning, language generation, or nuanced understanding, the closed-source leaders still tend to have an edge.
Support Limitations
With a closed-source provider, you benefit from their investment in documentation, technical support, API stability, and a managed service experience designed to support millions of users. With an open-source model, official vendor support does not exist unless you engage a third-party hosting provider. You rely on community forums, open-source documentation, and your own in-house expertise. For experienced teams, this is manageable. For teams without deep technical resources, it can be a significant barrier.
Safety and Alignment Challenges
Closed-source providers invest enormous effort in implementing safety filters, content guardrails, and alignment techniques that reduce the risk of harmful outputs. When you deploy an open-source model, the responsibility for implementing those safeguards falls entirely on you. If the model is improperly configured, inadequately secured, or deployed without appropriate safety measures, the risk of misuse or harmful outputs increases. You must be deliberate about building those protections into your deployment.
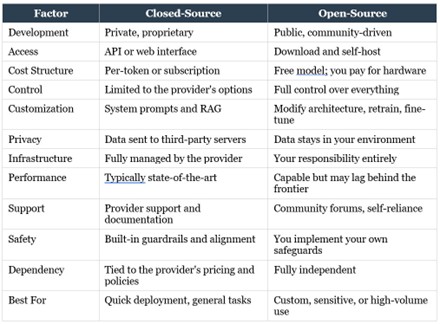
Side-by-Side Comparison
To bring all of these trade-offs into focus, in the next page is a comprehensive comparison of the two approaches.
Making the Choice: Key Decision Factors
When it comes to deciding between open-source and closed-source models, there is no universally correct answer. The right choice depends on your specific circumstances, and you should evaluate it across three dimensions.
Use Case Requirements
Start with what you are trying to accomplish. If your needs are general-purpose, such as summarization, content generation, question-answering, or conversational assistance, closed-source models will deliver excellent performance straight out of the box with minimal setup. If your needs are highly specialized, requiring the model to behave in very specific ways for a niche domain, open-source models offer the flexibility to fine-tune and customize far beyond what a closed-source API allows.
And if you are operating in a regulated industry with strict compliance requirements, open-source models may offer the data control you need to satisfy regulatory obligations.
Resource Availability
Be honest about what resources you have at your disposal. Open-source deployment requires technical talent, either on your team or available through a partner. It requires infrastructure, including compute capacity and DevOps expertise to manage it. And it requires an upfront investment in hardware and setup, even though the ongoing costs may be lower. Closed-source models, by contrast, require almost no technical setup. You pay more over time, but the barrier to getting started is minimal. If you lack the internal expertise or infrastructure to host models yourself, closed-source is the pragmatic starting point.
Strategic Priorities
Finally, consider your broader strategic goals. If control and independence are paramount, open-source keeps you free from vendor lock-in and gives you full ownership of your AI stack. If speed and convenience are your priorities, closed-source gives you the fastest access to the newest, most capable models without any infrastructure burden. If vendor strategy matters to your business, you need to decide whether you are comfortable being dependent on a specific provider or whether independence is worth the additional effort.
The Hybrid Approach: The Best of Both Worlds
In practice, many organizations find that the smartest strategy is not to choose one approach exclusively, but to combine both. This hybrid model is increasingly common and tends to work exceptionally well in the real world.
The logic is straightforward. Use closed-source models for your general-purpose tasks where their out-of-the-box performance, speed, and convenience deliver maximum value with minimum friction. Generating summaries, drafting outreach messages, categorizing data, answering customer inquiries, and creating content: these are the kinds of tasks where a closed-source API is fast, effective, and worth the per-token cost.
Then, for tasks that involve sensitive data, strict compliance requirements, or high-volume workloads where cost optimization is critical, route those through open-source models running on your own infrastructure. Syncing CRM data that contains customer information, generating financial reports with proprietary figures, processing healthcare records, or running any workload where data privacy is non-negotiable: these are ideal candidates for open-source deployment.
This hybrid approach gives you the best of both worlds. You get flexibility, cost optimization, regulatory compliance where you need it, and the ability to innovate at your own pace. You are not locked into a single provider, and you are not burdened with hosting everything yourself. You allocate each task to the deployment model that makes the most sense for that specific use case.
If there is one recurring theme in the world of AI and automation, it is that hybrid approaches tend to outperform rigid, one-size-fits-all strategies. The ability to assess a situation, understand the trade-offs, and choose the right tool for the right job is the skill that separates capable AI practitioners from everyone else. And when it comes to open-source versus closed-source, that flexibility is your greatest asset.
Looking Ahead
The landscape of large language models is evolving at a breathtaking pace. Context windows are expanding, costs are falling, and the gap between open-source and closed-source performance continues to narrow. The future is likely to bring richer multimodal capabilities, where models seamlessly handle text, images, audio, and video. Outputs will become more factual and reliable. Reasoning abilities will deepen. Specialized models will emerge for specific industries and domains. And the overall accessibility of AI, both in terms of ease of use and affordability, will continue to improve.
For you, the practical implication is this: the framework you have built across these articles, understanding tokens, context windows, pricing, model families, model types, and now the open-source versus closed-source distinction, gives you a durable foundation for navigating whatever comes next. New models will be released, new providers will enter the market, and new capabilities will emerge. But the principles for evaluating and selecting the right tools will remain remarkably consistent.
If you have been using AI primarily through closed-source chatbot interfaces up to this point, you are in good company. That is where most people begin, and there is enormous value to be extracted from those tools alone. But now you also understand the broader landscape of options available to you, and as your confidence, your usage volume, and your strategic ambitions grow, you have the knowledge to expand into open-source, hybrid deployments, and more sophisticated AI architectures.
You are building not just skills, but judgment. And in a space that moves this quickly, judgment is the most valuable asset you can have.